
python数据分析与可视化
前言
视频推荐:黑马程序员
重点学习了Numpy,Pandas,Matplotlib三个库
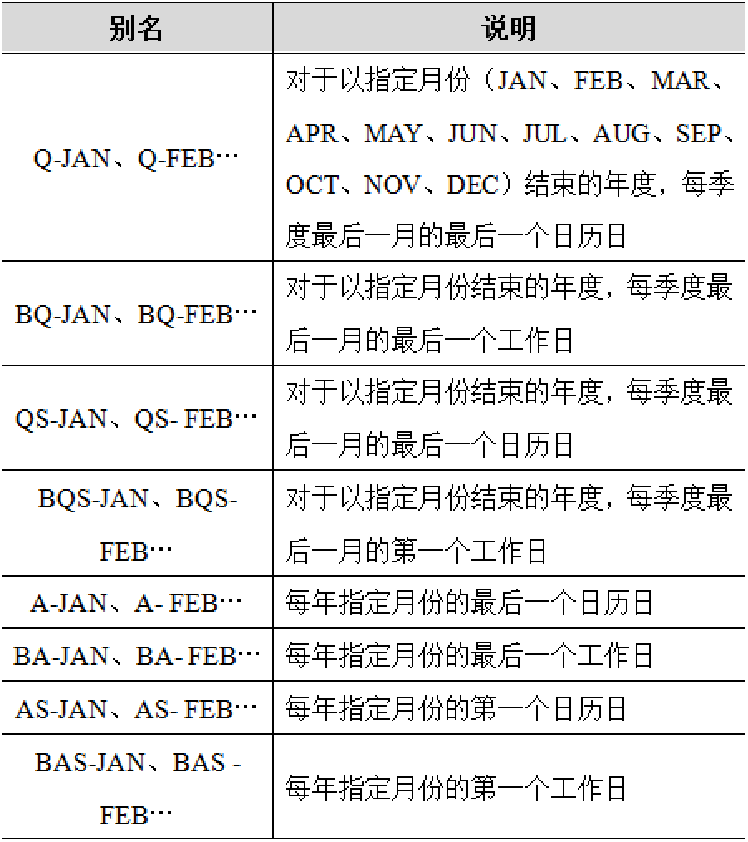
1.第一章 数据分析与可视化概述
1.什么是数据分析
数据分析是使用适当的统计分析方法对收集来的大量数据进行分析,从中提取有用信息和形成结论,并加以详细研究和概括总结的过程。
2.数据分析的流程
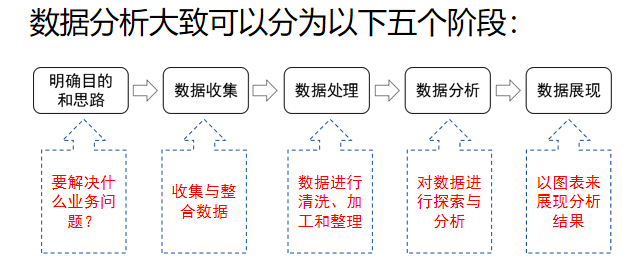
2.第二章 python编程基础
注:详细语法见Python编程
以下为个人认为容易忘记的知识点:
不可变数据类型:number 、string、tuple
变数据类型:list、dictionary 、set
运算符优先级:
逻辑<关系<算术
r” “ 的字符串方式,默认不转义
切片:[:]
range(start,end,step),生成为[,)的区间。
字典中的键必须唯一。
空集合只能使用set()创建。
“ “.join()连接字符串。
lambda函数:
1
2
3匿名函数:
a = lambda x,y,z:1+x*2+y*2+z*2
a(1,2,3)文件操作
打开文件:open()函数;
读取/写入文件:read()、readline()、readlines()、write()等;
对读取到的数据进行处理;
关闭文件:close()。
read([size]) 读取文件所有内容,返回字符串类型,参数size 表示读取的数量,以byte为单位,可以省略 readline([size]) 读取文件一行的内容,以字符串形式返回,若定义了size,则读出一行的一部分 readlines([size]) 读取所有的行到列表里面[line1,line2,…lineN],(文件每一行是list的一个成员),参数size表示读取内容的总长)
3.第三章 NumPy数值计算基础
1 | import numpy as np |
NumPy是Python的一种开源的数值计算扩展库。
它提供了两种基本的对象:
- ndarray:是储存单一数据类型的多维数组。
- ufunc:是一种能够对数组进行处理的函数。
ndarray是一个通用的同构数据容器,即其中的所有元素都需要相同的类型。
1 | i : int8,int16,int32,int64 |
1.array函数创建数组对象
1 | array函数的格式: |
| 参数名称 | 说明 |
|---|---|
| object | 接收array,表示想要创建的数组 |
| dtype | 接收data-type,表示数组所需的数据类型,未给定则选择保存对象所需的最小类型,默认为None |
| ndmin | 接收int,制定生成数组应该具有的最小维数,默认为None |
注:在创建数组时,NumPy会为新建的数组推断出一个合适的数据类型,并保存在dtype中。
1 | data = [x for x in range(10)] |
2.专门创建数组的函数
1.arange函数:创建数组
1 | 格式: |
2.linspace 函数:创建等差一维数组,接收元素数量作为参数。
1 | 语法: |
| 参数名称 | 说明 |
|---|---|
| start: | 起始值,默认从0开始; |
| stop: | 结束值;生成的元素不包括结束值; |
| num | 要生成的等间隔样例数量 |
3.logspace函数:创建等比一维数组
1 | 格式:np.logspace(start, stop, num, endpoint=True, base=10.0, dtype=None)) |
4.zeros函数:创建指定长度或形状的全0数组
1 | 格式:np.zeros(shape, dtype=float, order='C') |
5.ones函数:创建指定长度或形状的全1数组
1 | 格式:np. ones(shape, dtype=None, order='C') |
6.diag函数:创建一个对角阵。
1 | 格式: |
3.ndarray对象属性和数据转换
NumPy创建的 ndarray对象属性及其说明
| 属性 | 说明 |
|---|---|
| ndim | 返回数组的轴的个数 |
| shape | 返回数组的维度 |
| size | 返回数组元素个数 |
| dtype | 返回数据类型 |
| itemsize | 返回数组中每个元素的字节大小 |
1 | 1. |
4.生成随机数
1 | NumPy.random模块中,提供了多种随机数的生成函数。如randint函数生成指定范围的随机整数来构成指定形状的数组。 |
random模块的常用随机数生成函数
| 函数 | 说明 |
|---|---|
| seed | 确定随机数生成器的种子 |
| permutation | 返回一个序列的随机排列或返回一个随机排列的范围 |
| shuffle | 对一个序列进行随机排序 |
| binomial | 产生二项分布的随机数 |
| normal | 产生正态(高斯)分布的随机数 |
| beta | 产生beta分布的随机数 |
| chisquare | 产生卡方分布的随机数 |
| gamma | 产生gamma分布的随机数 |
| uniform | 产生在[0,1)中均匀分布的随机数 |
5.数组变换
1 | 数组重塑:数据重塑不会改变原来的数组 |
6.数组的索引和切片
1 | # 格式arr[1:1:10,::1:20] |
7.数组的运算
1 | 一.数组和标量间的运算 |
8.数组读写
1 | 一.NumPy中读写二进制文件的方法有: |
| 参数 | 使用说明 |
|---|---|
| fname | str,读取的CSV文件名 |
| delimiter | str,数据的分割符 |
| usecols | tuple(元组) ,执行加载数据文件中的哪些列 |
| unpack | bool,是否将加载的数据拆分为多个组,True表示拆,False不拆 |
| skipprows | int,跳过多少行,一般用于跳过前几行的描述性文字 |
| encoding | bytes,编码格式 |
9.Numpy中的数据统计与分析
1 | 一.排序 |
| 参数 | 使用说明 |
|---|---|
| a | 要排序的数组 |
| kind | 排序算法,默认为“quicksort” |
| order | 排序的字段名,可指定字段排序,默认为None |
| axis | 使得sort函数可以沿着指定轴对数据集进行排序。axis=1为沿横轴排序;axis=0为沿纵轴排序;axis=None,将数组平坦化之后进行排序 |
1 | 间接排序: |
10.重复数据与去重
1 | 一.对于一维数组或者列表,unique函数去除其中重复的元素,并按元素由大到小返回一个新的元组或者列表。 |
4.第四章 Pandas统计分析基础
1 | import pandas as pd |
Pandas有三种数据结构:Series、DataFrame和Panel。
Series类似于一维数组;
DataFrame是类似表格的二维数组;
Panel可以视为Excel的多表单Sheet。
1.Pandas的数据结构
1.Series
1 | Series 是一种一维数组对象,包含了一个值序列,并且包含了数据标签,称为索引(index),可通过索引来访问数组中的数据。 |
2.DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
1 | 格式: |
DataFrame的属性:
| 函数 | 返回值 |
|---|---|
| values | 元素 |
| index | 索引 |
| columns | 列名 |
| dtypes | 类型 |
| size | 元素个数 |
| ndim | 维度数 |
| shape | 数据形状(行列数目) |
2.索引对象
1 | 1.索引对象 |
每个索引都有一些方法和属性,它们可用于设置逻辑并回答有关该索引所包含的数据的常见问题。Index的常用方法和属性:
| 方法 | 说明 |
|---|---|
| append | 连接另一个Index对象,产生一个新的Index |
| diff | 计算差集,并得到一个Index |
| intersection | 计算交集 |
| union | 计算并集 |
| isin | 计算一个指示各值是否都包含在参数集合中的布尔型数组 |
| delete | 删除索引i处的元素,并得到新的Index |
| drop | 删除传入的值,并得到新的Index |
| insert | 将元素插入到索引i处,并得到新的Index |
| is_monotonic | 当各元素均大于等于前一个元素时,返回True |
| is.unique | 当Index没有重复值时,返回True |
| unique | 计算Index中唯一值的数组 |
1 | 插入索引值 |
DataFrame的基础属性有values、index、columns、dtypes、ndim和shape,分别可以获取DataFrame的元素、索引、列名、类型、维度和形状。
1 | df.values |
3.Pandas索引操作
重置索引:指对索引重新排序而不是重新命名,如果某个索引值不存在的话,会引入缺失值。
1
2
3
4
5
6
7
8
9
10
11
12语法:
DataFrame.reindex(labels = None,index = None,columns = None,axis = None,method = None,copy = True,level = None,fill_value = nan,limit = None,tolerance = None)
其中:
index:用作索引的新序列。
method:插值填充方式。
fill_value:引入缺失值时使用的替代值。
limit:前向或者后向填充时的最大填充量。
method:使用相邻的元素值进行填充(ffill向前填充,bfill向后,nearest最近的索引值填充)
obj = pd.Series([7,-1,4,3],index=['b','a','c','d'])
print(obj)
obj.reindex(['a','b','c','d','e'])更换索引
1
2
3
4
5不使用默认的行索引时,set_index()实现
df4 = df3.set_index('city')
df4
reset_index()还原索引,重新恢复索引为默认的整型索引
4.DataFrame数据的查询与编辑
1.DataFrame数据的查询
选取列
1
2w1 = df4[['name','year']]
print(w1)选取行
1
2
3
4
5
6
7
8
9
10
11
12
13通过切片的方式选取
df4[:2]
df4[1:3]
此外:
head() #默认获取前5行
head(n)#获取前n行
tail()#默认获取后5行
tail(n)#获取后n行
sample(n)#随机抽取n行显示
sample(frac=0.6) #随机抽取60%的行
df4.head(2)选取行和列:切片选取行具有很大的局限性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23语法:
DataFrame.loc(行索引名称或条件,列索引名称)
DataFrame.iloc(行索引位置,列索引位置)
1.loc的数据选取
df4.loc[['北京','上海'],['name','year']]
df4.loc[df4['year']>=2002,['name','year']]
2.loc和isin配合使用
df4.loc[df4['year'].isin(['2001','2003'])] # 查询2001和2003年的数据
3.使用iloc选取行和列
df4.iloc[:,2]
df4.iloc[[1,3],[0,2]] # 1和3行,0和2列
4.使用pandas的query方法
语法:
DataFrame.query(self,expr,inplace,**kwargs) # expr要评估的查询字符串
df4.query('year > 2001 & year <2003')
5.布尔选择:使用逻辑运算符前要加() # & | !=
df = pd.DataFrame({'price':[1,3,5,5,4,5,3]})
df[(df.price >= 2) & (df.price <= 4)]
2.DataFrame数据的编辑
将需要编辑的数据提取出来,重新赋值
增加数据
1
2
3
4
5
6
71.增加一行直接通过append方法传入字典结构数据即可。ignore_index设置是否忽略原Index。
data = {'city':'兰州','name':'李红','year':2005,'sex':'female'}
df1.append(data,ignore_index=True)
2.增加列时,只需为要增加的列赋值即可创建一个新的列。若要指定新增列的位置,可以用insert函数。
df1['score'] = [10,12,13,14]
df1.insert(1,'No',[1,2,3,4])删除数据
1
2drop方法,axis指定,默认删除不修改原数据,加上inplace=True可以原数据删除。
df4.drop('广州',inplace=True)修改数据:直接对选择的数据赋值即可。
1
2
3
4还可以使用replace进行数据的替换
DataFrame.replace(to_replace=None,value=None,inplace=False,limit=None,regex=False,method='pad')
参数to_replace表示被替换的值,value表示替换后的值。
同时替换多个值时使用字典数据,如DataFrame.replace({'B':'E','C':'F'})表示将表中的B替换为E,C替换为F修改列名
1
2
3Pandas通过DataFrame.rename()函数,传入需要修改列名的字典形式来修改列名。
df4.rename(columns={'no':'number'},inplace=True)
5.Pandas数据运算
1.算术运算
Pandas执行算术运算时,会先按照索引进行对齐,对齐以后再进行相应的运算,没有对齐的位置会用NaN进行补齐。(数据对齐)
NAN填充缺失数据,则可以在调用add方法时提供fill_value参数的值。
1 | obj_one.add(obj_two, fill_value = 0) |
2.排序
按索引排序
使用sort_index()方法,该方法可以用行索引或者列索引进行排序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18sort_index(axis = 0,level = None,ascending = True,inplace = False,kind =' quicksort ',na_position='last',sort_remaining = True )
axis:轴索引,0表示index(按行),1表示columns(按列)。
level:若不为None,则对指定索引级别的值进行排序。
ascending:是否升序排列,默认为True表示升序。
1.对Series进行分别排序
ser_obj = pd.Series(range(10, 15), index=[5, 3, 1, 3, 2])
# 按索引进行升序排列
ser_obj.sort_index()
# 按索引进行降序排列
ser_obj.sort_index(ascending = False)
2.按索引对DataFrame进行分别排序,axis指定方向
df_obj = pd.DataFrame(np.arange(9).reshape(3, 3),index=[4, 3, 5])
# 按行索引升序排列
df_obj.sort_index()
# 按行索引降序排列
df_obj.sort_index(ascending=False)按值排序
Pandas中用来按值排序的方法为sort_values()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16sort_values(by,axis=0, ascending=True, inplace=False, kind='quicksort',na_position='last')
by参数表示排序的列
na_position参数只有两个值:first和last,若设为first,则会将NaN值放在开头;若设为False,则会将NaN值放在最后。
1.
ser_obj = pd.Series([4, np.nan, 6, np.nan, -3, 2])
# 按值升序排列
ser_obj.sort_values()
2.
df_obj = pd.DataFrame([[0.4, -0.1, -0.3, 0.0],
[0.2, 0.6, -0.1, -0.7],
[0.8, 0.6, -0.5, 0.1]])
# 对列索引值为2的数据进行排序
df_obj.sort_values(by=2)
3.统计计算与描述
常用方法:
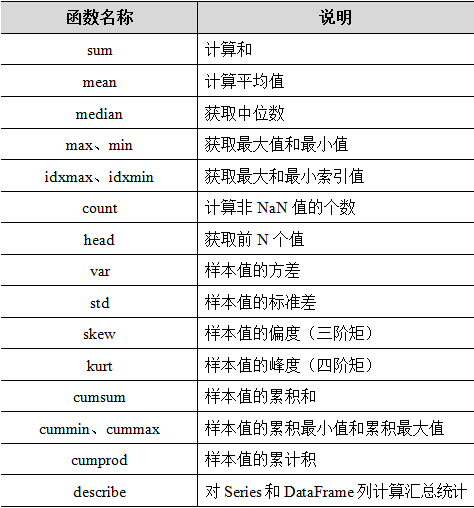
1 | 如果希望一次性输出多个统计指标,则调用describe()方法实现,语法: |
4.层次化索引
两层索引结构:分为内层索引和外层索引。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
271.
Series和DataFrame均可以实现层次化索引,最常见的方式是在构造方法的index参数中传入一个嵌套列表。
注意:在创建层次化索引对象时,嵌套函数中两个列表的长度必须是保持一致的,否则将会出现ValueError错误。
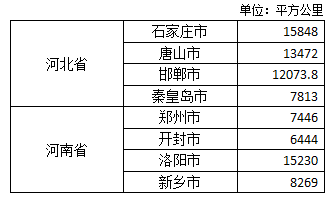
mulitindex_series = pd.Series([15848,13472,12073.8,7813,7446,6444,15230,8269],
index=[['河北省','河北省','河北省','河北省','河南省','河南省','河南省','河南省'],
['石家庄市','唐山市','邯郸市','秦皇岛市','郑州市','开封市','洛阳市','新乡市']])
2.通过MultiIndex类的方法构建一个层次化索引
MultiIndex.from_tuples() # 将元组列表转换为MultiIndex。
MultiIndex.from_arrays() # 将数组列表转换为MultiIndex。
MultiIndex.from_product() # 从多个集合的笛卡尔乘积中创建一个MultiIndex。
eg:
list_tuples = [('A','A1'), ('A','A2'), ('B','B1'),('B','B2'), ('B','B3')]
# 根据元组列表创建一个MultiIndex对象
multi_index = MultiIndex.from_tuples(tuples=list_tuples,names=[ '外层索引', '内层索引'])
multi_array = MultiIndex.from_arrays(arrays =[['A', 'B', 'A', 'B', 'B'],
['A1', 'A2', 'B1', 'B2', 'B3']],
names=['外层索引','内层索引'])
numbers = [0, 1, 2]
colors = ['green', 'purple']
multi_product = pd.MultiIndex.from_product(iterables=[numbers, colors],names=['number', 'color'])
6.数据分组与聚合
- 分组是指使用特定的条件将原数据划分为多个组
- 聚合指的是对每个分组中的数据执行某些操作,最后将计算的结果进行整合。
- 分组与聚合的过程大概分为以下三步:
- 拆分:将数据集按照一些标准拆分为若干个组。
- 应用:将某个函数或方法(内置和自定义均可)应用到每个分组。
- 合并:将产生的新值整合到结果对象中。
1.数据的分组
1 | groupby()方法将数据集按照某些标准划分成若干个组。 |
按列名进行分组
1
2
3
4
5
6
7
8df.groupby(by='Key')
查看每个分组的具体内容:
group_obj = df.groupby('Key')
# 遍历分组对象
for i in group_obj:
print(i)按Series对象进行分组
1
2
3
4
5
6
7
8
9
10
11
12ser_obj = pd.Series(['a', 'b', 'c', 'a', 'b'])
# 按自定义Series对象进行分组
group_obj = df.groupby(by = ser_obj)
如果Series对象与Pandas对象的索引长度不相同时,则只会将具有相同索引的部分数据进行分组。
df = se = pd.Series(['a', 'a', 'b'])
group_obj = df.groupby(se)['one', 'two', 'one','two', 'one'],
'data1': [2, 3, 4, 6, 8],
'data2': [3, 5, 6, 3, 7]})
se = pd.Series(['a', 'a', 'b'])
group_obj = df.groupby(se)按字典进行分组
1
当使用字典对DataFrame进行分组时,则需要确定轴的方向及字典中的映射关系,即字典中的键为列名,字典的值为自定义的分组名。
按函数进行分组
1
2
3将函数作为分组键会更加灵活,任何一个被当做分组键的函数都会在各个索引值上被调用一次,返回的值会被用作分组名称。
# 使用内置函数len进行分组
groupby_obj = df.groupby(len)
2.数据的聚合
1 | 自定义函数,将它作为参数传给agg()方法,实现Pandas对象的聚合运算。 |
对每一列数据应用同一个函数
1
2
3
4
5
6通过agg()方法进行聚合,最简单的方式就是给该方法的func参数传入一个函数,这个函数既可以是内置的,也可以自定义的。
def range_data_group(arr):
return arr.max()-arr.min()
# 使用自定义函数聚合分组数据
data_group.agg(range_data_group)对某列数据应用不同的函数
1
2
3
4
5
6
7
8
9可以将两个函数的名称放在列表中,之后在调用agg()方法进行聚合时作为参数传入即可。
# 对一列数据用两种函数聚合
data_group.agg([range_data_group, sum])
为了能更好地反映出每列数据的信息,可以使用“(name,function)”元组将function(函数名)替换为name(自定义名称)。
data_group.agg([("极差", range_data_group), ("和", sum)])对不同列数据应用不同函数
1
2
3如果希望对不同的列使用不同的函数,则可以在agg()方法中传入一个{"列名":"函数名"}格式的字典。
data_group.agg({'a': 'sum', 'b': 'mean', 'c': range_data_group})
3.分组运算
- 如果希望聚合后的数据与原数据保持一样的形状,那么可以通过transfrom()方法实现。
1 | transform(func, *args, **kwargs) |
- apply()方法的使用是十分灵活的,它可以在许多标准用例中替代聚合和转换,另外还可以处理一些比较特殊的用例。
1 | apply(func, axis=0, broadcast=None, raw=False, reduce=None,result_type=None, args=(), **kwds) |
5.第五章 Pandas数据的载入与预处理
1.数据载入
1.读写文本文件
CSV文件是一种纯文本文件,可以使用任何文本编辑器进行编辑,它支持追加模式,节省内存开销。
写入CSV文件
1
2
3
4to_csv(path_or_buf=None,sep=',',na_rep='',float_format=None,columns=None,header=True, index=True,index_label=None, mode='w‘, ...)
path_or_buf:文件路径。
index:默认为True,若设为False,则将不会显示索引。
sep:分隔符,默认用“,”隔开。读取CSV文件
1
2
3
4
5read_csv(filepath_or_buffer,sep=',', delimiter=None, header='infer', names=None, index_col=None,usecols=None, prefix=None, ...)
sep:指定使用的分隔符,默认用“,”分隔。
header:指定行数用来作为列名。
names:用于结果的列名列表。如果文件不包含标题行,则应该将该参数设置为None。Text文件
如果希望读取Text文件,既可以用前面提到的read_csv()函数,也可以使用read_table()函数。(read_csv()与read_table()函数的区别在于使用的分隔符不同,前者使用“,”作为分隔符,而后者使用“\t”作为分隔符。)
2.读写Excel文件
扩展名为.xls和.xlsx文件两种
写入
1
2
3
4
5
6to_excel(excel_writer,sheet_name='Sheet1',na_rep='',float_format=None, columns=None, header=True, index=True, ...)
excel_writer:表示读取的文件路径。
sheet_name:表示工作表的名称,默认为“Sheet1”。
na_rep:表示缺失数据。
index:表示是否写行索引,默认为True。读取
1
2
3
4
5
6pandas.read_excel(io,sheet_name=0,header=0,names=None,index_col=None, **kwds)
io:表示路径对象。
sheet_name:指定要读取的工作表,默认为0。
header:用于解析DataFrame的列标签。
names:要使用的列名称。
3.读写JOSN文件
读取
1
2
3
4读取时会顺序变乱,需要排序
import pandas as pd
df = pd.read_json('Filename')
df = df.sort_index写入
1
pd.to_json
4.读取HTML表格数据
1 | pandas.read_html(io, match='.+', flavor=None,header=None, index_col=None,skiprows=None, attrs=None) |
5.读写数据库文件
为了高效地读取数据库中的数据,这里需要引入SQLAlchemy。
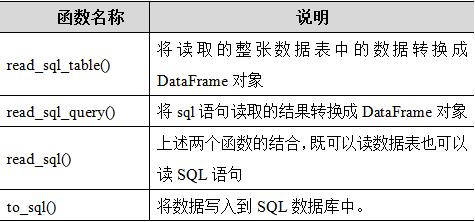
1 | read_sql()函数既可以读取整张数据表,又可以执行SQL语句。 |
2.合并数据
1.merge数据合并
通过1个或多个键将2个DataFrame按行合并起来
1 | pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, |
2.concat数据连接
需要合并的DataFrame之间没有连接键。默认按行方向堆叠数据。使用axis修改方向。
1 | pd.concat(objs,axis=0,join='outer',ignore_index=False,keys=None, |
3.combine_first合并数据
1 | 当DataFrame对象中出现了缺失数据,而使用其他DataFrame对象中的数据填充缺失数据 |
4.join()方法合并
通过索引或指定列来连接多个DataFrame对象。
1 | join(other,on = None,how ='left',lsuffix ='',rsuffix ='',sort = False ) |
3.数据清洗
数据清洗的目的提高数据质量,将脏数据清洗干净,使原数据具有完整性、唯一性、权威性、合法性、一致性等特点。
脏数据:指的是对数据分析没有实际意义、格式非法、不在指定范围内的数据。
1.空值(None)和缺失值(NaN)的处理
空值一般表示数据未知、不适用或将在以后添加数据。
缺失值是指数据集中某个或某些属性的值是不完整的。
检查或处理空值和缺失值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
201.使用isnull()和notnull()函数可以判断数据集中是否存在空值和缺失值。(通过info方法查看每列数据的缺失情况)
pandas.isnull(obj) # 如果返回的结果为True,则说明有空值或缺失值
2.对于缺失数据可以使用dropna()和fillna()方法对缺失值进行删除和填充。
dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
axis:确定过滤行或列。
how:确定过滤的标准。
thresh:表示有效数据量的最小要求。若传入了2,则是要求该行或该列至少有两个非NaN值时将其保留。
fillna(value=None, method=None, axis=None, inplace=False,limit=None, downcast=None, **kwargs)
value:用于填充的数值。
method:表示填充方式,默认值为None。
limit: 可以连续填充的最大数量,默认None。
注:method参数不能与value参数同时使用。
# 使用66.0替换缺失值
df_obj.fillna('66.0')
# 指定列填充数据
df_obj.fillna({'A': 4.0, 'B': 5.0})
2.重复值的处理
Pandas提供了两个函数专门用来处理数据中的重复值,分别为duplicated()和drop_duplicates()方法。
1 | duplicated()方法用于标记是否有重复值。有为True |
3.异常值的处理
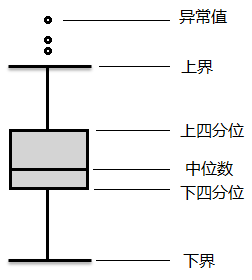
异常值是指样本中的个别值,其数值明显偏离它所属样本的其余观测值,这些数值是不合理的或错误的。
检测方法有散点图,3σ原则(拉依达准则)和箱形图。
散点图
通过数据分布的散点图发现异常数据
箱形图:boxplot()方法
是一种用作显示一组数据分散情况的统计图
1
2
3
4异常值通常被定义为小于QL – 1.5QR或大于QU + 1.5IQR的值。
(1)QL称为下四分位数,表示全部观察中四分之一的数据取值比它小;
(2)QU称为上四分位数,表示全部观察值中有四分之一的数据取值比它大;
(3)IQR称为四分位数间距,是上四分位数QU与下四分位数QL之差,其间包含了全部观察值的一半。
3σ原则,又称为拉依达原则,它是指假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,凡是超过这个区间的误差都是粗大误差,在此误差的范围内的数据应予以剔除。
1
2
3(1)数值分布在(μ-σ,μ+σ)中的概率为0.682。
(2)数值分布在(μ-2σ,μ+2σ)中的概率为0.954。
(3)数值分布在(μ-3σ,μ+3σ)中的概率为0.997。
通常会采用如下四种方式处理这些异常值:
1 | 1.直接将含有异常值的记录删除。 |
4.数据转换
1 | 不仅可以对单个数据进行替换,也可以多个数据执行批量替换操作。 |
5.重塑层次化索引
stack()方法和unstack()方法,前者是将数据的列“旋转”为行,后者是将数据的行“旋转”为列。
1 | stack()方法可以将数据的列索引转换为行索引。 |
4.数据变换与数据离散化
1.类别数据的哑变量的处理
哑变量又称虚拟变量、名义变量,从名称上看就知道,它是人为虚设的变量,用来反映某个变量的不同类别。
使用哑变量处理类别转换,事实上就是将分类变量转换为哑变量矩阵或指标矩阵,矩阵的值通常用“0”或“1”表示。
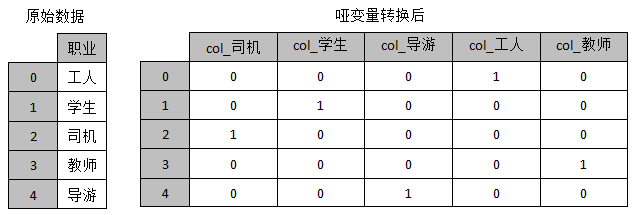
1 | 对类别特征进行哑变量处理: |
2.连续性变量的离散化
1 | cut ()函数能够实现离散化操作。 |
6.第六章 Matplotlib数据可视化基础
数据可视化按照数据类型分类:
- 时空数据可视化
- 层次与网络结构数据可视化
- 文本和跨媒体数据可视化
- 多变量数据可视化
1.Matplotlib简介
可以绘制
- 直方图:适于比较数据之间的多少。
- 折线图:反映一组数据的变化趋势。
- 条形图:显示各个项目之间的比较情况,和直方图有类似的作用。(用宽度相同的条形的高度或者长短来表示数据多少的图形,可以横置或纵置,纵置时也称为柱形图。)
- 散点图:显示若干数据系列中各数值之间的关系。
- 箱形图:识别异常值方面有一定的优越性。
2.Matplotlib绘图基础
1 | 在Jupyter Notebook中进行交互式绘图需要执行: |
1.创建画布与子图
创建新的空白画布
如果不希望在默认的画布上绘制图形,则可以调用figure()函数构建一张新的空白画布。
1
2
3
4
5
6
7
8matplotlib.pyplot.figure(num = None,figsize = None,dpi = None, facecolor = None,edgecolor = None, ...,** kwargs)
num -- 表示图形的编号或名称。
figsize -- 用于设置画布的尺寸。
facecolor -- 用于设置画板的背景颜色。
edgecolor -- 用于显示边框颜色。
figure_obj = plt.figure() # 调用figure()函数创建新的空白画布。建画布时为其添加背景颜色
1
2
3
4
5
6
7
8
9设置facecolor参数。
data_two = np.arange(200, 301)
# 创建背景为灰色的新画布
plt.figure(facecolor='gray')
# 通过data2绘制折线图
plt.plot(data_two)
plt.show()创建子图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
361.
figure对象允许划分为多个绘图区域,每个绘图区域都是一个axes对象,它拥有属于自己的坐标系统,被称为子图。
语法:
subplot(nrows, ncols, index, **kwargs)
nrows,ncols -- 表示子区网格的行数、列数。
index -- 表示矩阵区域的索引。
注:按照从左到右、从上到下的顺序对每个区域进行编号。其中,位于左上角的子区域编号为1,依次递增。
如果nrows、ncols和index这三个参数的值都小于10,则可以把它们简写为一个实数。(subplot(3,2,3)==subplot(323))
fig = plt.figure()
ax1 = plt.subplot(2,2,1)
ax2 = plt.subplot(2,2,2)
ax1.plot([1,2,3,4,5])
ax2.plot([1,2,3,4,5])
2.一次性创建一组子图
subplots(nrows = 1,ncols = 1,sharex =False,sharey = False,squeeze = True,subplot_kw = None,gridspec_kw = None,** fig_kw)
nrows,ncols -- 表示子区网格的行数、列数。
sharex,sharey -- 表示控制x或y轴是否共享。
subplots()函数会返回一个元组,元组的第一个元素为Figure对象(画布),第二个元素为Axes对象(子图,包含坐标轴和画的图)或Axes对象数组。
import numpy as np
fig,axes = plt.subplots(2,2,sharex=True,sharey=True)
for i in range(2):
for j in range(2):
axes[i,j].hist(np.random.randn(500),bins=50,color='k',alpha=0.5)
plt.subplots_adjust(wspace=0,hspace=0)
3.通过Figure类的add_subplot()方法添加和选中子图。
add_subplot(* args,** kwargs )
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax1.plot([1,2,3,4,5])
2.添加画布内容
1 | 实例: |
3.图表正确显示中文
1 | plt.rcParams['font.sans-serif']=['SimHei'] |
4.绘图的保存与显示
本地保存图形
1
2
3plt.savefig(fname, dpi=None, facecolor='w', edgecolor='w', ...)
fname参数是一个包含文件名路径的字符串,或者是一个类似于Python文件的对象。如果format 参数设为None且fname参数是一个字符串,则输出格式将根据文件名的扩展名推导出来。显示图形
1
plt.show
3.Pyplot中的常用绘图
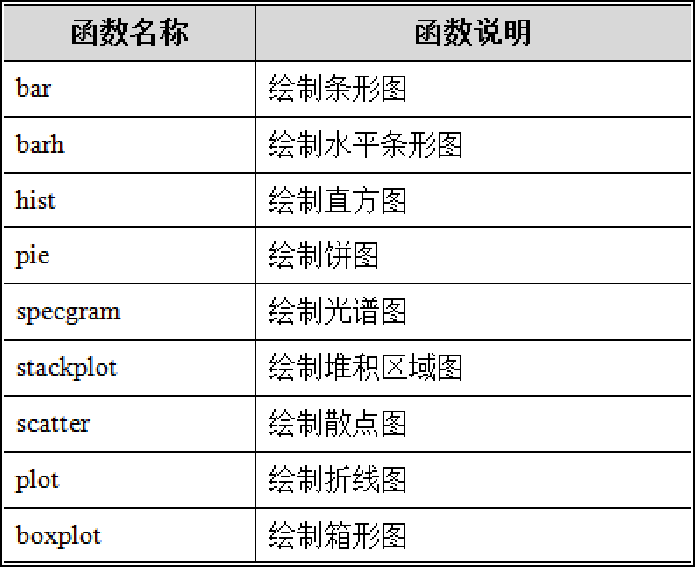
- 常见的图形绘制函数
1.颜色、线型、标记的设置
颜色
线型值
标记
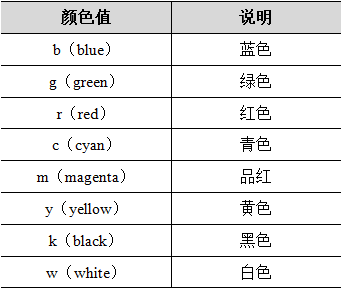
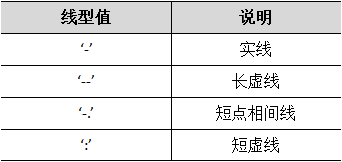
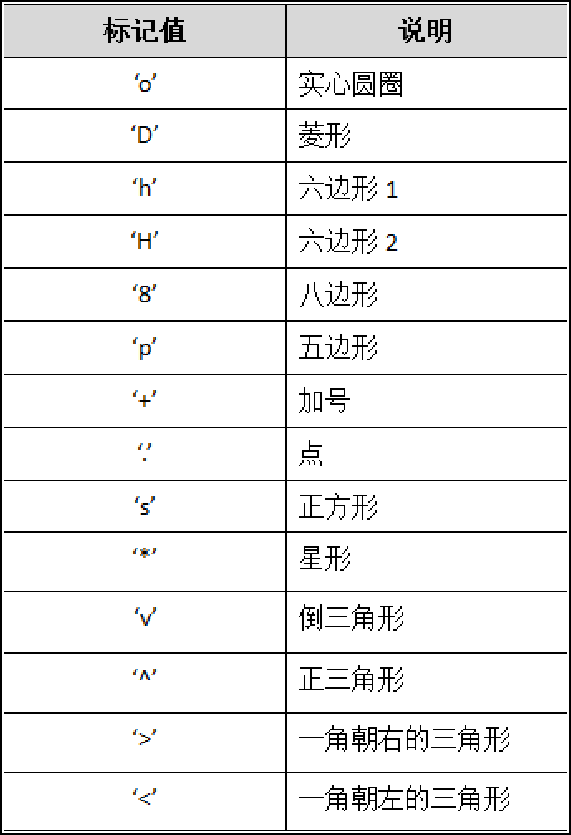
2.折线图
1 | matplotlib.pyplot.plot(*args,**kwargs) |
3.直方图
1 | matplotlib.pyplot.hist(x,bins = None,range = None,color = None,label = None, ..., ** kwargs) |
4.散点图
1 | matplotlib.pyplot.scatter(x, y, s=None, c=None, marker=None, alpha=None, linewidths=None, ..., **kwargs) |
5.柱状图
1 | matplotlib.pyplot.bar(x, height, width, *, align='center', **kwargs) |
结果:
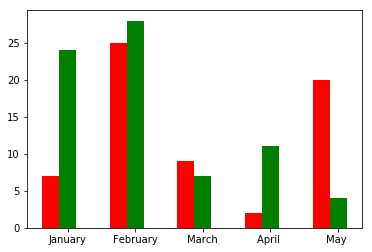
6.饼图
1 | matplotlib.pyplot.pie(x,explode,labels,color,autopct,pctdistance,labeldistance,radius) |
7.箱线图
1 | matplotlib.pyplot.boxplot(X,notch,sym,vert,positions,widths,labels,meanline) |
8.概率图
1 | from scipy.stats import norm |
4.图标辅助元素的定制
1.认识图表常用的辅助元素
- 坐标轴:分为单坐标轴和双坐标轴,单坐标轴按不同的方向又可分为水平坐标轴(又称x轴)和垂直坐标轴(又称y轴)。
- 标题:表示图表的说明性文本。图例:用于指出图表中各组图形采用的标识方式。
- 网格:从坐标轴刻度开始的、贯穿绘图区域的若干条线,用于作为估算图形所示值的标准。
- 参考线:标记坐标轴上特殊值的一条直线。
- 参考区域:标记坐标轴上特殊范围的一块区域。
- 注释文本:表示对图形的一些注释和说明。
- 表格:用于强调比较难理解数据的表格。
2.设置坐标轴的标签
1 | 设置x轴的标签: |
3.设置刻度范围和刻度标签
1 | 1.设置x轴的刻度范围 |
4.添加标题
1 | title(label, fontdict=None, loc=‘center’, pad=None, **kwargs) |
5.添加图例
1 | legend(handles, labels, loc, bbox_to_anchor, ncol, title, shadow, fancybox, *args, **kwargs) |
6.显示指定样式的网格
可分为垂直网格和水平网格
1 | grid(b=None, which='major', axis='both', **kwargs) |
7.添加参考线
分为水平参考线,垂直参考线
1 | 1.添加水平参考线: |
8.添加参考区域
1 | 1.添加水平参考区域 |
9.文本注解
1 | 1.添加无指向型注释文本 |
10.数学表达式
自动识别使用annotate()或text()函数传入的数学字符串,并解析成对应的数学表达式。
1 | 要求字符串以美元符号“$”为首尾字符,且首尾字符中间包裹数学表达式。 |
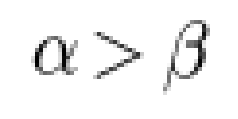
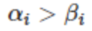
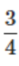
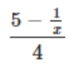
11.添加表格
1 | table(cellText=None, cellColours=None, cellLoc='right', colWidths=None, …, **kwargs) |
12.绘图的填充
1 | fill_between()填充区域 |
7.第七章 时间序列数据分析
什么是时间序列?
时间序列是指多个时间点上形成的数值序列,它既可以是定期出现的,也可以是不定期出现的。
时间序列的数据主要有:
- 时间戳:表示特定的时刻,比如现在。
- 时期:比如2018年或者2018年10月。
- 时间间隔:由起始时间戳和结束时间戳表示。
1.时间序列的基本操作
创建时间序列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Pandas中,时间戳使用Timestamp(Series派生的子类)对象表示。
pd.to_datetime('20180828')
传入的是多个datetime组成的列表,则Pandas会将其强制转换为DatetimeIndex类对象。
date_index = pd.to_datetime(['20180820','20180828','20180908'])
最基本的时间序列类型就是以时间戳为索引的Series对象。
date_ser = pd.Series([11, 22, 33], index=date_index)
将包含多个datetime对象的列表传给index参数,同样能创建具有时间戳索引的Series对象。
date_list = [datetime(2018, 1, 1), datetime(2018, 1, 15]
time_se = pd.Series(np.arange(6), index=date_list)
如果希望DataFrame对象具有时间戳索引
data_demo = [[11, 22, 33], [44, 55, 66]]
date_list = [datetime(2018, 1, 23), datetime(2018, 2, 15)]
time_df = pd.DataFrame(data_demo, index=date_list)通过时间戳索引选取子集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21最简单的选取子集的方式,是直接使用位置索引来获取具体的数据。
time_se[3] # 根据位置索引获取数据
使用datetime构建的日期获取其对应的数据。
date_time = datetime(2015, 6, 1)
date_se[date_time]
在操作索引时,直接使用一个日期字符串(符合可以被解析的格式)进行获取。
date_se['20150530']
date_se['2018/01/23']
获取某年或某个月的数据,则可以直接用指定的年份或者月份操作索引。
date_se['2015']
除了使用索引的方式以外,还可以通过truncate()方法截取 Series或DataFrame对象。
truncate(before = None,after = None,
axis = None,copy = True)
before -- 表示截断此索引值之前的所有行。
after -- 表示截断此索引值之后的所有行。
axis -- 表示截断的轴,默认为行索引方向。
2.固定频率的时间序列
创建固定频率的时间序列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Pandas中提供了一个date_range()函数,主要用于生成一个具有固定频率的DatetimeIndex对象。
date_range(start = None, end = None, periods = None, freq = None, tz = None, normalize = False, name = None, closed = None,** kwargs)
start:表示起始日期,默认为None。
end:表示终止日期,默认为None。
periods:表示产生多少个时间戳索引值。
freq:用来指定计时单位。
则默认生成的时间戳是按天计算的,即freq参数为D。
如果只是传入了开始日期或结束日期,则还需要用periods参数指定产生多少个时间戳。
pd.date_range(start='2018/08/10', periods=5)
pd.date_range(end='2018/08/10', periods=5)
如果希望时间序列中的时间戳都是每周固定的星期日,将freq参数设为“W-SUN”。
dates_index = pd.date_range('2018-01-01', periods=5, freq='W-SUN')
日期中带有与时间相关的信息,且想产生一组被规范化到当天午夜的时间戳,可以将normalize参数的值设为True。
pd.date_range(start='2018/8/1 12:13:30',
periods=5, normalize=True, tz='Asia/Hong_Kong')时间序列的频率、偏移量
1
2默认生成的时间序列数据是按天计算的,即频率为“D”。
“5D”表示每5天。1
2
3
4
5
6
7每个基础频率还可以跟着一个被称为日期偏移量的DateOffset对象,需要先导入pd.tseries.offsets模块后才行。
from pandas.tseries.offsets import *
DateOffset(months=4, days=5)
还可以使用offsets模块中提供的偏移量类型进行创建。
Week(2) + Hour(10)时间序列的移动
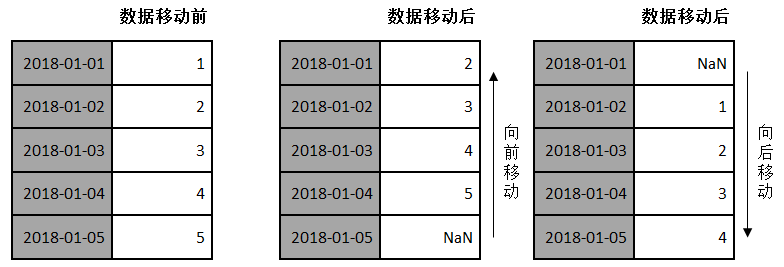
移动是指沿着时间轴方向将数据进行前移或后移。
1
2
3
4Pandas对象中提供了一个shift()方法,用来前移或后移数据,但数据索引保持不变。
shift(periods=1, freq=None, axis=0)
periods -- 表示移动的幅度,可以为正数,也可以为负数,默认值是1,代表移动一次。

3.时间周期及计算
创建时期对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29Period类表示一个标准的时间段或时期,比如某年、某月、某日、某小时等。
创建Period类对象的方式比较简单,只需要在构造方法中以字符串或整数的形式传入一个日期即可。
pd.Period(2018)
pd.Period('2017/6')
Period对象能够参与数学运算
period = pd.Period('2017/6')
period + 1
相同频率的两个Period对象进行数学运算
pd.Period('2017/6')
other_period = pd.Period(201201, freq='M' )
period - other_period
如果希望创建多个Period对象,且它们是固定出现的,则可以通过period_range()函数实现。
period_index = pd.period_range('2012.1.8','2012.3.31', freq='M')
除了使用上述方式创建PeriodIndex外,还可以直接在PeriodIndex的构造方法中传入一组日期字符串。
str_list = ['2010', '2011', '2012']
pd.PeriodIndex(str_list, freq='A-DEC')
asfreq()方法来转换时期的频率。
asfreq(freq,method = None,how = None,normalize = False,fill_value = None )
freq -- 表示计时单位。
how -- 可以取值为start或end,默认为end。
normalize -- 表示是否将时间索引重置为午夜。
fill_value -- 用于填充缺失值的值。
4.重采样
重采样方法(resample)
1
2
3
4
5
6
7
8
9
10
11
12
13Pandas中的resample()是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, ...)
rule -- 表示重采样频率的字符串或DateOffset。
fill_method -- 表示升采样时如何插值。
closed -- 设置降采样哪一端是闭合的。
time_ser.resample('W-MON').mean()
how参数不再建议使用,而是采用新的方式“.resample(...).mean()”求平均值。
如果重采样时传入closed参数为left,则表示采样的范围是左闭右开型的。
time_ser.resample('W-MON', closed='left').mean()降采样
1
2
3
4
5
6
7
8
9
10
11降采样时间颗粒会变大,数据量是减少的。为了避免有些时间戳对应的数据闲置,可以利用内置方法聚合数据。
股票数据比较常见的是OHLC重采样,包括开盘价、最高价、最低价和收盘价。
date_index = pd.date_range('2018/06/01', periods=30)
shares_data = np.random.rand(30)
time_ser = pd.Series(shares_data, index=date_index)
time_ser.resample('7D').ohlc()
降采样相当于另外一种形式的分组操作,它会按照日期将时间序列进行分组,之后对每个分组应用聚合方法得出一个结果。
time_ser.groupby(lambda x: x.week).mean()升采样
1
2
3
4
5
6
7升采样的时间颗粒是变小的,数据量会增多,这很有可能导致某些时间戳没有相应的数据。
常用的解决办法就是插值,具体有如下几种方式:
1.通过ffill(limit)或bfill(limit)方法,取空值前面或后面的值填充,limit可以限制填充的个数。
2.通过fillna(‘ffill’)或fillna(‘bfill’)进行填充,传入ffill则表示用NaN前面的值填充,传入bfill则表示用后面的值填充。
3.使用interpolate()方法根据插值算法补全数据。
5.数据统计—滑动窗口
滑动窗口指的是根据指定的单位长度来框住时间序列,从而计算框内的统计指标。(相当于一个长度指定的滑块在刻度尺上面滑动,每滑动一个单位即可反馈滑块内的数据。)
1 | rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None) |
6.时序模型—ARIMA
ARIMA的全称叫做差分整合移动平均自回归模型,又称作整合移动平均自回归模型,是一种用于时间序列预测的常见统计模型。
ARIMA模型主要由AR、I与MA模型三个部分组成。
1 | 记作:ARIMA(p,d,q) |



